Before jumping directly into the upgrade, it’s worth highlighting a few important points.
This blog post is not only about upgrading the OpenShift Logging Operator — it also covers how to continue sending logs without disrupting external systems that use Fluentd Forward.
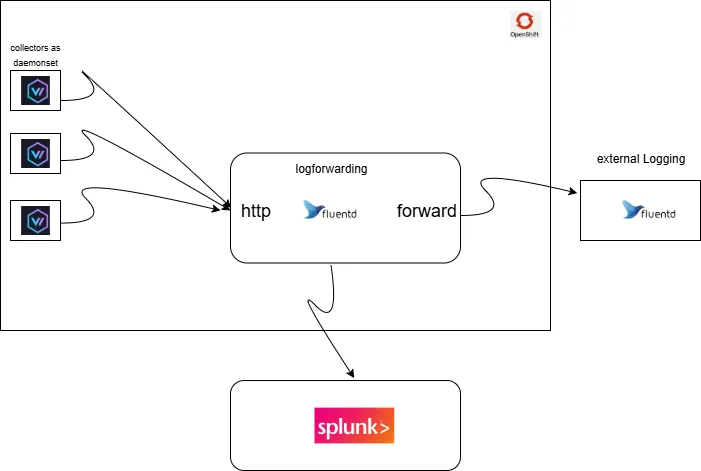
To achieve this, we’ll introduce an additional Aggregator component (via Log Forwarding), shown in the diagram below. This component receives OpenShift/Kubernetes logs over HTTP, applies necessary transformations, and then forwards them to external logging systems — such as those using Fluentd Forward or SIEM solutions like Splunk.
In this upgrade approach, we won’t be performing a direct upgrade from version 5.x to 6.x.Instead, we’ll remove the OpenShift Logging Operator 5 and install the OpenShift Cluster Logging Operator 6 from scratch.
Also, note that we won’t deploy the full Operator stack (which includes the LokiStack for log storage).
This post focuses only on the collector and forwarder components. The Loki setup will be covered in a separate blog post.
Only update to an N+2 version, where N is your current version. For example, if
you are upgrading from Logging 5.8, select stable-6.0 as the update channel.
Updating to a version that is more than two versions newer is not supported.
Upgrading the OpenShift Logging Operator from version 5.x to 6.x introduces several breaking changes due to significant technological and architectural updates in the operator. Some of the key changes are listed below.
- Only supported collector agent now is vector. So, fluentd is not supported anymore.
- Since fluentd is not a supported collector Fluentdforward is not available as output type.
- Elasticsearch is replaced with Loki
- Kibana is replaced with the UIplugin provided by COO.
- The API for log collection is changed from logging.openshift.io to
- observability.openshift.io.
- ClusterLogForwarder and ClusterLogging have been combined under the ClusterLogForwarder resource in the new API.
As mentioned at the beginning of this post, with the upgrade to Logging Operator 6, FluentdForward is no longer an available output type.
If you still rely on FluentdForward for external integrations, there’s a workaround using the LogForwarding component. You can think of this component as a log aggregator and routing layer — it collects logs, processes them, and forwards them to external systems while maintaining compatibility with existing Fluentd-based setups.
Uninstall Openshift Logging Operator 5
Do not to forget to make backup of resources before deleting CRDs other definitions deleted below.
oc -n openshift-logging delete subscription cluster-logging
oc -n openshift-logging delete operatorgroup openshift-logging
oc -n openshift-logging delete clusterserviceversion cluster-logging<old-version>
oc delete crd clusterlogforwarders.logging.openshift.io
oc delete crd clusterloggings.logging.openshift.io
oc delete crd logfilemetricexporters.logging.openshift.io
Make sure there is no any residue from Openshift Logging Operator 5.
Install OpenShift Logging Operator 6
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: openshift-logging
namespace: openshift-logging
spec:
targetNamespaces:
- openshift-logging
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: cluster-logging
namespace: openshift-logging
spec:
channel: stable-6.0
installPlanApproval: Automatic
name: cluster-logging
source: redhat-operators
sourceNamespace: openshift-marketplace
startingCSV: cluster-logging.v6.0.7Create necessary service account and assign necessary ClusterRoles to the Service Account.
oc create sa logging-collector -n openshift-logging
oc adm policy add-cluster-role-to-user collect-application-logs -z logging-collector -n
openshift-logging
oc adm policy add-cluster-role-to-user collect-audit-logs -z logging-collector -n
openshift-logging
oc adm policy add-cluster-role-to-user collect-infrastructure-log -z logging-collector -n
openshift-loggingDefine ClusterLogForwarder Definition
apiVersion: observability.openshift.io/v1
kind: ClusterLogForwarder
metadata:
name: instance
namespace: openshift-logging
spec:
collector:
tolerations: {}
inputs:
- application:
includes:
- namespace: ns1
name: ns1
type: application
- application:
includes:
- namespace: ns2
name: ns2
type: application
outputs:
- http:
url: http://logforwarding.openshift-logging.svc:24224/kubernetes/var/log/pods/appgrp
name: appgrp
type: http
- http:
url: http://logforwarding.openshift-logging.svc:24224/kubernetes/var/log/pods/extlogging
name: externallogging
type: http
- http:
url: http://logforwarding.openshift-logging.svc:24224/kubernetes/splunk
name: splunk
type: http
pipelines:
- inputRefs:
- audit
name: audit
outputRefs:
- splunk
- inputRefs:
- infrastructure
name: infrastructure
outputRefs:
- splunk
- inputRefs:
- application
name: application
outputRefs:
- splunk
- inputRefs:
- ns1
name: ns1
outputRefs:
- appgrp
- inputRefs:
- ns2
name: ns2
outputRefs:
- appgrp
- externallogging
serviceAccount:
name: logging-collectorDeploy Logforwarding Component
The LogForwarding component is not part of the Cluster Logging Operator. Instead, it serves as a separate log aggregation and forwarding layer that can send logs over various protocols.
Since the new Logging Operator no longer supports FluentdForward, this component will receive logs over HTTP and forward them using your desired protocols.
You can easily deploy this component using a Helm chart or a simple YAML definition. In this post, I’ll share only the ConfigMap definition for the Fluentd configuration.
If your environment handles a large volume of logs or requires high throughput, consider using Fluent Bit instead of Fluentd for better performance.
fluent.conf: |
<system>
log_level info
</system>
<source>
@type http
@id input1
port 24224
bind 0.0.0.0
</source>
<filter kubernetes.var.log.pods.appgrp>
@type record_transformer
enable_ruby
<record>
time-filename ${Time.new.strftime("%Y%m%d_%H%M")}
</record>
</filter>
<filter kubernetes.var.log.pods.extlogging>
@type record_transformer
remove_keys $.kubernetes.annotations
</filter>
<match kubernetes.var.log.pods.appgrp>
@type rewrite_tag_filter
<rule>
key $.kubernetes.namespace_name
pattern ^(.+)$
tag $1.${tag}
</rule>
</match>
<match kubernetes.var.log.pods.extlogging>
@type forward
@id upstream
transport tcp
require_ack_response true
<server>
host extlogging.openshift-logging.svc
port 24224
</server>
<buffer>
@type file
flush_interval 60s
flush_mode interval
flush_thread_count 2
overflow_action block
path /var/log/fluentd/extlogging-buffer
retry_max_interval 30
retry_max_times 3
retry_timeout 60s
retry_type exponential_backoff
total_limit_size 600m
</buffer>
</match>
<match *.kubernetes.var.log.pods.appgrp>
@type file
path /var/log/fluentd/backup/${tag[0]}/${tag[0]}.${$.time-filename}
compress gzip
<buffer tag,$.time-filename>
@type file
flush_interval 300s
flush_mode interval
flush_thread_count 2
overflow_action block
path /var/log/fluentd/backup-buffer/${tag}/${tag}
retry_max_interval 30
retry_max_times 3
retry_timeout 60s
retry_type exponential_backoff
total_limit_size 600m
</buffer>
</match>
<match ** >
@type splunk_hec
protocol https
insecure_ssl false
hec_host splunk
sourcetype <source type>
source <your source>
index <index>
hec_port 443
hec_token <splunk token>
host "#{ENV['NODE_NAME']}"
<buffer>
@type memory
chunk_limit_records 100000
chunk_limit_size 200m
flush_interval 5s
flush_thread_count 1
overflow_action block
retry_max_times 3
total_limit_size 600m
</buffer>
</match>
Leave a Reply